ROWID Reuse in SQLite Databases
Recently on one of the list-serves I'm on; a question was raised about whether ID's can be reused in an SQLite database. Whilst the database in question does not reuse ID's, it does bring up the question of does SQLite ever reuse ID's? The short answer is under certain circumstances YES they can! and the long answer requires an understanding of how rowid's work in SQLite, so let's get into that.
ROWID's Explained
For faster sorting and searching, SQLite implemented a special field called rowid that uniquely identifies a record in a table. This unique identifier is considered the true primary key and is what is actually used by the underlying B-tree storage mechanism to look up records in a table. The only exception to this is what they call a WITHOUT ROWID table, which uses the declared primary key as the identifier.
When a table has an integer primary key declared, then this field becomes an alias of the rowid, so both fields will contain the same value. In fact, if you look at a record at the physical level for a table that has an integer primary key, the serial type for the primary key column will be 0 which means NULL.
Note: The declared field type for an integer primary key must be the word INTEGER exactly. If the field is just INT, BIGINT, INT64 or something similar then it will be treated as its own field rather than becoming an alias for the rowid.
If the Primary Key is a non-integer field such as text or if a composite key is defined (multiple columns combined as a primary key) then the Primary Key and rowid will be different, but still the rowid is considered the true primary key for searching and sorting purposes.
SQLite does allow tables to be created without a primary key. So even if that is the case, rowid is used to uniquely identify records.
How are ROWID's Assigned?
The configuration of a primary key determines the behavior of how rowid's are assigned. The default behavior is to assign a new record with a rowid that is the largest EXISTING rowid value + 1. This is also the way rowid's are assigned if the primary key is a non-integer or if no primary is declared.
If the primary key has been set to AUTOINCREMENT then new records will be assigned a rowid that is the largest EVER rowid used + 1. In this scenario an internal SQLite table called sqlite_sequence will be present in the database and used to track the highest rowid.
Default ROWID Assignment Example
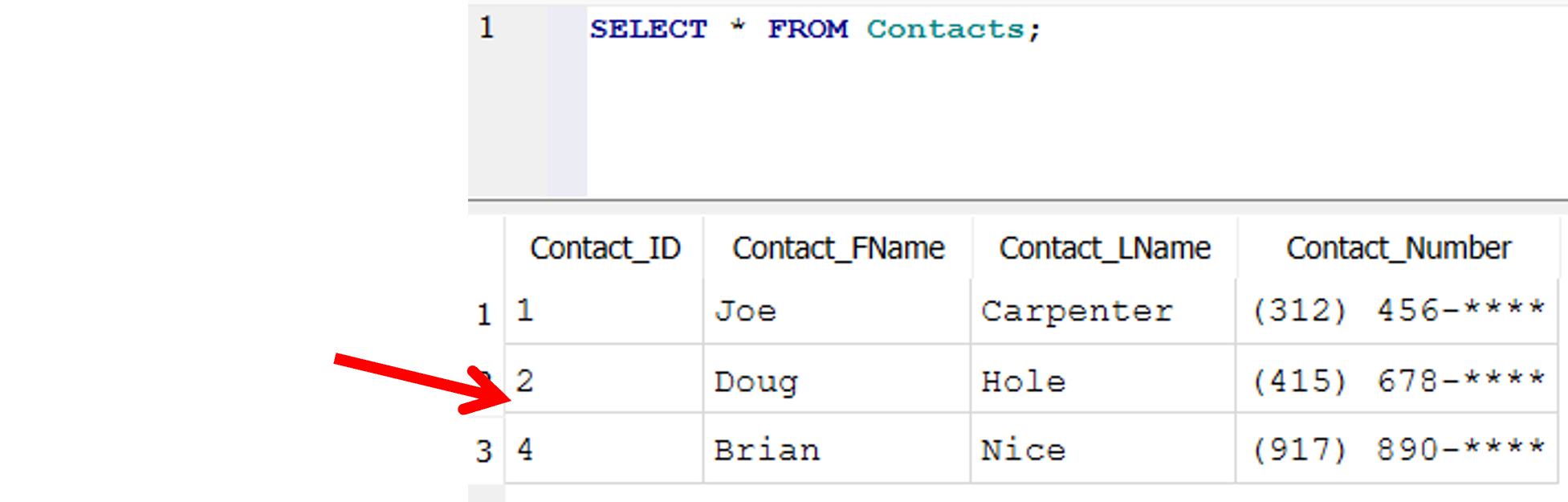
I created a real simple database with 1 table that has Contact_ID as an Integer Primary Key, so this field becomes an alias of the rowid.
CREATE TABLE [Contacts]([Contact_ID] INTEGER PRIMARY KEY, [Contact_FName] TEXT NOT NULL, [Contact_LName] TEXT NOT NULL, [Contact_Number] TEXT);



AUTOINCREMENT Example
I created the same Contacts table again, but this time I configured the Contact_ID as autoincrementing primary key.
CREATE TABLE [Contacts]([Contact_ID] INTEGER PRIMARY KEY AUTOINCREMENT, [Contact_FName] TEXT NOT NULL, [Contact_LName] TEXT);
As I used AUTOINCREMENT, the sqlite_sequence table was created. This table is an internal table that tracks the largest rowid ever used in tables that have auto-incrementing primary keys.
The sqlite_sequence table contains 2 fields:
- Name: Name of the table with an autoincrementing integer primary key
- seq: The largest rowid EVER used in the table. Incremented by 1 for each record that is inserted into the table.

I inserted the same initial 4 records to this database, deleted the record for Mark Lorenzo, and then inserted a new record. The rowid's came out the same as the previous example where we have a gap in the values.

The entry for the Contacts table in the sqlite_sequence table is updated to 5.

How can ROWID's be reused?
We have established how SQLite assigns rowid's and because rowid is considered the true primary key for a table you will never find 2 allocated records with the same rowid. Let's now look at how rowid's can be reused.
The scenario where a rowid can be reused is when the table primary key is not set to autoincrement, and the last inserted record(s) are deleted. With this scenario, As the sqlite_sequence table is not tracking the highest rowid ever used, it takes the highest EXISTING rowid.
I will walkthrough an example in my contacts database where I didn't set the Contact_ID to autoincrement. I deleted the last 2 contacts I inserted with Holly Berry being id 5 and Brian Nice being 4.

I then inserted 2 new records into the table. From the database perspective it doesn't know that ID's 3 - 5 have been previously used, so the new records are assigned ID 3 and 4.

Identifying Reused ID's
The identification of reused ID's is dependent on if the deIeted record can be recovered from the main database file or the journal files.
First step is to determine if the rowid's can be reused in the table of interest (no sense in going down the rabbit hole if you don't need to). Easiest way is to look for the presence of the sqlite_sequence table and if it is present, query it to see what tables are being tracked.
SELECT * FROM sqlite_sequence
Once you have established that there is the possibility that the rowid can be reused, you will need to compare the active records with the deleted records that your tool was able to recover. Be mindful that your tool must be able to recover the row_id for a record in order for this to work.
I used my SQLite tool to extract records from the main database file and the associated WAL file.
Note: The Analysis_ID, Source, Frame, Page and File_Offset columns are auto generated by my tool and may not be provided by the tool that you use.






Comments
Post a Comment